

Technical Brief: Why Traditional LAN Architectures Are a Mismatch for Modern Real-Time Systems -- and Long-Reach PCIe Solves the Problem
Overview
Modern System Requirements
Predictable latency
Deterministic timing
Shared memory resources
The architecture of modern computing systems is undergoing a fundamental transition. Historically, distributed computing environments were designed around node-centric architectures, where independent servers communicated through Ethernet networks. These architectures worked well for batch processing workloads where throughput mattered more than timing precision.
Today's emerging applications -- particularly AI inference at the edge, real-time simulation, robotics, autonomous systems, and distributed sensor processing -- have very different requirements. These systems require tightly synchronized compute resources that must exchange data with predictable latency, deterministic timing, and direct access to shared memory resources.
Traditional LAN-based architectures were never designed for these constraints.
A new approach is emerging: long-reach PCI Express (PCIe) fabrics, which extend the native interconnect used inside computers across multiple systems. This approach allows distributed compute resources to behave like a single coherent machine, enabling deterministic performance at scale.
The Shift in AI and Real-Time Workloads
Modern compute workloads are evolving rapidly, particularly with the growth of Real-Time and autonomous systems. Historically, workloads were designed around large centralized systems performing batch processing tasks. Data was collected, processed asynchronously, and results were generated later.
Today, many systems must make decisions in real time.
AI workloads have evolved from:
From
Batch processing
To
Real-time, distributed decision-making
From
Throughput-first processing
To
Latency-, determinism-, and synchronization-sensitive execution
From
Isolated server nodes
To
Tightly coupled multi-accelerator systems
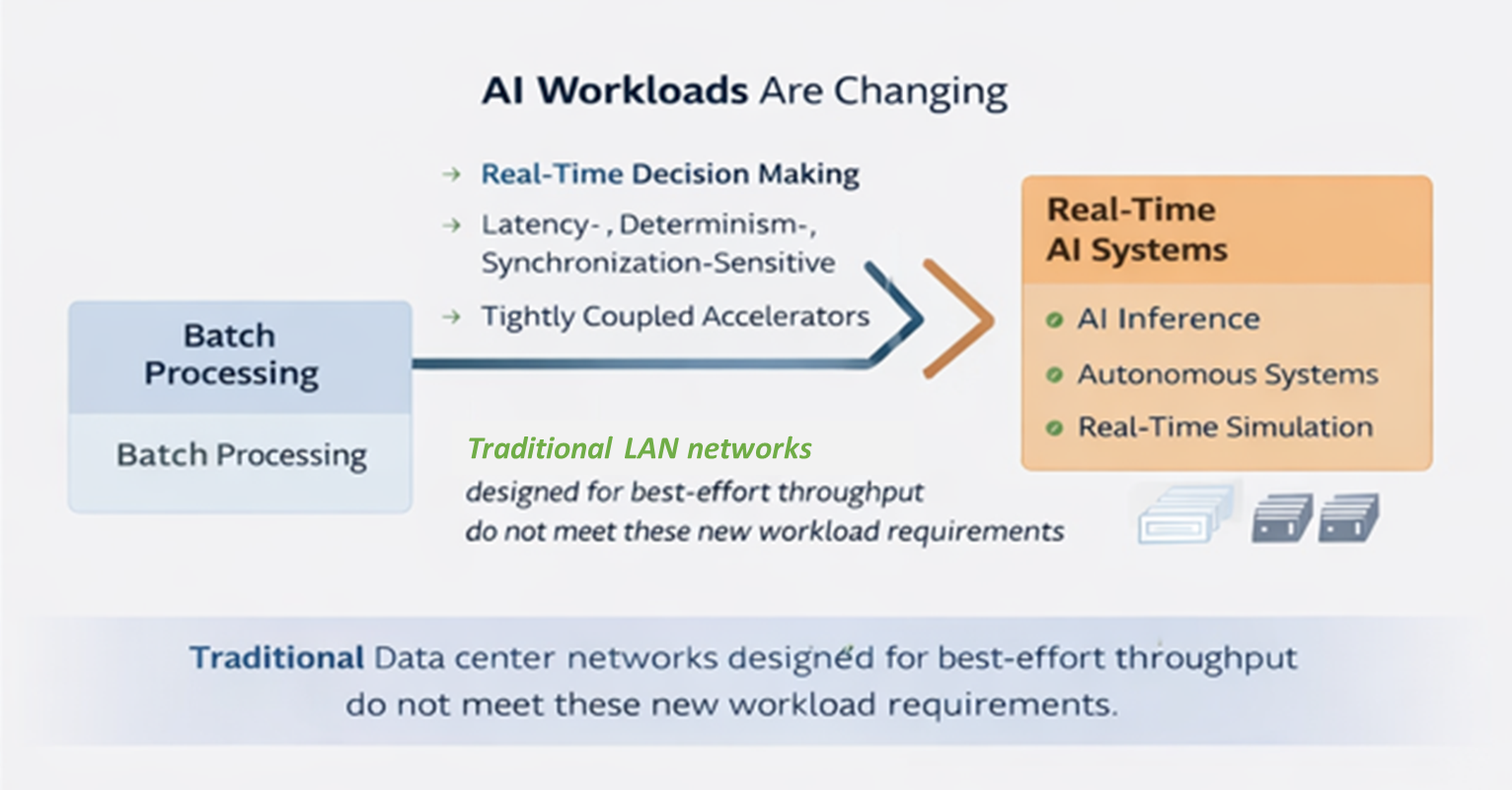
These new workloads increasingly rely on combinations of CPUs, GPUs, FPGAs, and specialized accelerators that must exchange data continuously while operating in tight synchronization. Examples include:
Real-time AI inference systems
Autonomous vehicles and robotics
Defense and aerospace sensor fusion
High-performance simulation environments
Financial trading platforms
Distributed AI training clusters
In these environments, predictable timing matters as much as raw throughput.
Why Traditional LAN Architectures Fall Short
Most distributed systems today rely on Ethernet networks and the TCP/IP protocol stack for communication between compute nodes. While Ethernet is ubiquitous and well understood, it was designed as a best-effort packet delivery system, not as a deterministic compute fabric. This design introduces several limitations for real-time and tightly coupled applications.
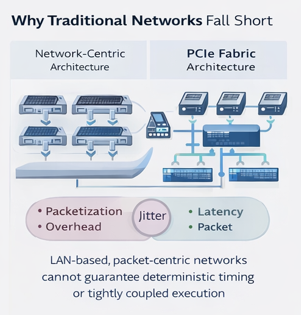
01
Best-Effort Networking
Ethernet networks are optimized for maximizing throughput across many independent users. However, real-time systems require:
Deterministic latency
Guaranteed delivery timing
Predictable system behavior under load
Traditional networks cannot guarantee these properties.
02
Packetization Overhead
Ethernet communication requires data to be broken into packets, transmitted, routed through switches, and reassembled at the destination. This introduces:
Latency
Jitter (timing variation)
Buffering delays
Software processing overhead
Even high-speed networks such as 100G or 400G Ethernet cannot eliminate these architectural inefficiencies.
03
No Shared Memory Model
Traditional network architectures treat each node as an independent system. This means:
No shared memory space
No direct device-to-device communication
All communication must be explicitly packaged and transmitted through network stacks
This dramatically increases complexity and limits system performance.
04
Performance Degrades Under Load
As systems scale, network congestion and switching delays introduce unpredictable behavior. This results in:
Increased latency
Greater jitter
Reduced synchronization across compute nodes
For real-time systems, these effects can make architectures unusable at scale.
Scaling Network Bandwidth Does Not Solve the Problem
A common approach to improving performance is simply increasing network bandwidth. Over the past decade, Ethernet speeds have progressed rapidly:
25G
100G
200G
400G
800G
While higher bandwidth improves throughput, it does not address the fundamental architectural limitations of packet-based networking.
Key issues remain:
Latency remains relatively high
Packet overhead remains unavoidable
Synchronization challenges remain
Deterministic performance is still not guaranteed
As a result, increasing network speed often leads to higher cost, greater power consumption, and increased system complexity without solving the underlying architectural mismatch.
PCI Express: The Native Interconnect of Modern Compute
Inside every modern computer system, high-performance devices communicate through PCI Express (PCIe).
PCIe is the industry-standard interconnect used to connect:
CPUs
GPUs
FPGAs
AI accelerators
High-speed storage
Network interfaces
Specialized hardware devices

Unlike Ethernet, PCIe was designed specifically for direct device-to-device communication with deterministic performance. Key characteristics include:
Extremely low latency
Direct memory access (DMA)
Peer-to-peer communication
High bandwidth density
Deterministic performance behavior
Minimal attack surface due to absence of routable protocols and reduced software stack
PCIe is governed by the PCI-SIG industry consortium, ensuring interoperability across thousands of vendors and products.
Why PCIe Matters Now
Several major trends are driving increased adoption of PCIe-based architectures.
Predictable Performance Scaling
PCIe has one of the most predictable performance roadmaps in the industry. Each generation roughly doubles bandwidth while maintaining backward compatibility.
Example: PCIe Gen 4 → Gen 5 → Gen 6 → Gen 7. This ensures long-term infrastructure investment protection.
| Performance demanded today | ||||||||
| PCIe Generation | Gen 1 | Gen 2 | Gen 3 | Gen 4 | Gen 5 | Gen 6 | Gen 7 | Gen 8 |
| Specification Released | 2003 | 2007 | 2010 | 2017 | 2019 | 2022 | 2025 | 2028 |
| Total Bandwidth (x16) | 4.0 GB/s | 8.0 GB/s | 16.0 GB/s | 32.0 GB/s | 64.0 GB/s | 128.0 GB/s | 256.0 GB/s | 512.0 GB/s |
Accelerator-Driven Computing
AI systems increasingly rely on multiple specialized accelerators. These devices must exchange large volumes of data quickly and deterministically. PCIe provides the native interface used by these accelerators, making it the natural backbone for next-generation architectures.
Increasing System Density
Modern compute systems are packing more GPUs and accelerators into smaller spaces. As density increases, traditional networking architectures become inefficient. PCIe fabrics enable high-density compute clusters with minimal communication overhead.
Introducing Long-Reach PCIe Fabrics
Traditionally, PCIe has been limited to connections within a single server motherboard.
Recent advances in switching, signaling, and system architecture now allow PCIe to be extended beyond a single system. This approach is known as long-reach PCIe.
Long-reach PCIe fabrics extend the native PCIe interconnect across multiple systems while preserving PCIe's core characteristics. This enables distributed compute resources to function as a single coherent compute environment. Key capabilities include:
Extending PCIe beyond the server chassis
Maintaining native PCIe semantics across distance
Enabling direct device-to-device communication
Allowing shared memory access across systems
The result is a distributed infrastructure that behaves much like a single large computer rather than a collection of loosely connected servers.
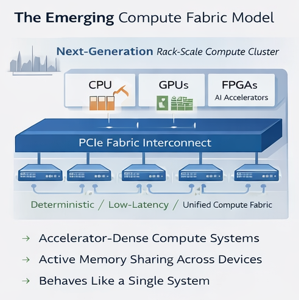
Long-Reach PCIe Architectural Benefits
Long-reach PCIe architectures offer several important advantages over traditional LAN-based systems.
1
Deterministic Performance: Communication occurs through direct memory access rather than packet routing, eliminating jitter and unpredictable network delays.
2
Ultra-Low Latency: PCIe communication occurs at nanosecond-scale latency, significantly faster than Ethernet-based communication.
3
Simplified System Architecture: By removing networking layers, PCIe fabrics reduce system complexity and improve operational efficiency.
4
Higher Accelerator Utilization: Direct communication between GPUs, FPGAs, and other accelerators allows workloads to be distributed more efficiently across available hardware.
5
Lower Power and Hardware Overhead: Reducing reliance on NICs, switches, and networking infrastructure can significantly lower system power consumption and infrastructure cost.
Security Implications: Long-Reach PCIe Reduces Exposure to Zero-Day Attacks
Traditional LAN-based architectures introduce a broad and dynamic attack surface due to their reliance on standardized networking protocols, routable packet flows, and software-defined control planes. These characteristics make them inherently vulnerable to both known exploits and zero-day attacks.
In contrast, long-reach PCIe fabrics fundamentally reduce attack exposure by eliminating many of the mechanisms that attackers rely on.
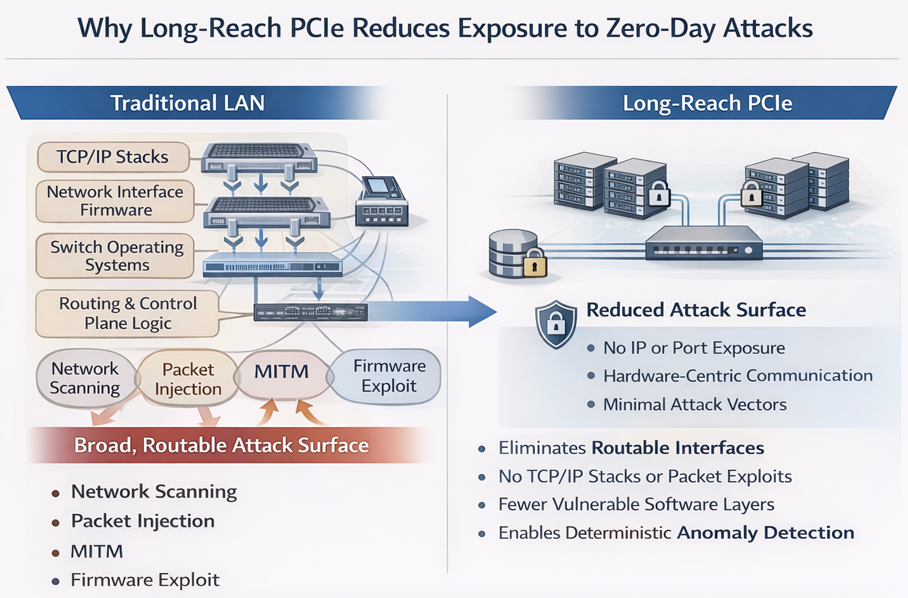
Reduced Attack Surface
Ethernet-based systems depend on multiple layers of software and protocol processing, including:
TCP/IP stacks
Network interface firmware
Switch operating systems
Routing and control-plane logic
Each layer represents a potential vulnerability, particularly for zero-day exploits.
Long-reach PCIe eliminates these layers, replacing them with a hardware-centric, memory-mapped communication model. Fewer abstraction layers directly translate to fewer exploitable entry points.
Elimination of Routable Interfaces
Traditional LAN-connected systems expose IP addresses and open ports, making them discoverable and targetable across networks.
PCIe fabrics:
Do not use IP addressing
Do not expose services via open ports
Are not routable using standard networking tools
This effectively removes entire classes of remote attack vectors, including:
Network scanning
Port-based exploitation
Remote service attacks
No Packet Injection or Man-in-the-Middle Opportunities
Ethernet architectures rely on packetized communication, which enables:
Packet interception
Injection attacks
Replay attacks
Protocol manipulation
PCIe operates as a point-to-point, transaction-based fabric with no concept of packets traversing shared networks. As a result:
There is no opportunity for packet interception or injection
Man-in-the-middle attacks are structurally eliminated
Deterministic Behavior Enables Anomaly Detection
LAN-based systems exhibit variable latency and jitter, making it difficult to distinguish between normal behavior and malicious interference.
PCIe fabrics provide deterministic, predictable timing. This enables:
Easier detection of anomalous behavior
Faster identification of compromised components
Reduced dwell time for zero-day exploits
Hardware-Centric Trust Model
Because PCIe communication is tightly coupled to hardware and memory access:
Access paths are explicit and controlled
Devices must be enumerated and authorized
Communication is not dynamically exposed like network services
This aligns well with zero-trust architectures by enforcing strict boundaries at the hardware level.
Security Comparison: Traditional LAN vs Long-Reach PCIe
| Capability | Traditional LAN | Long-Reach PCIe |
|---|---|---|
| Routable (IP-based) | Yes | No |
| Exposed ports/services | Yes | No |
| Packet injection risk | Yes | No |
| Protocol attack surface | High | Minimal |
| Software stack dependency | High | Low |
| Deterministic behavior | No | Yes |
| Zero-day exposure | Broad | Constrained |
Implications for Defense and Mission-Critical Systems
For environments where adversaries actively develop zero-day capabilities, reducing attack surface is often more effective than attempting to detect every possible exploit.
Long-reach PCIe enables:
Physically constrained communication paths
Elimination of network-based intrusion vectors
Greater system survivability under active cyber attack
As Long-Reach PCIe is structurally more secure by design, it is better suited for
Zero-day resilience
Electronic Warfare (EW) and congested environments
Air-gapped or hardened systems
Deep Memory Recording: High-Speed, Multi-Source Data Capture at Scale
Modern real-time systems increasingly require the ability to capture, store, and analyze massive volumes of data across distributed sensors and compute elements. Examples include:
Defense sensor fusion and electronic warfare
High-speed RF signal capture
Autonomous system telemetry
AI training data collection in live environments
These applications demand deep memory recording--the ability to ingest and store large amounts of data continuously, at high speed, and from multiple sources simultaneously.
Deep Memory Recording: Ethernet vs. PCIe Fabric
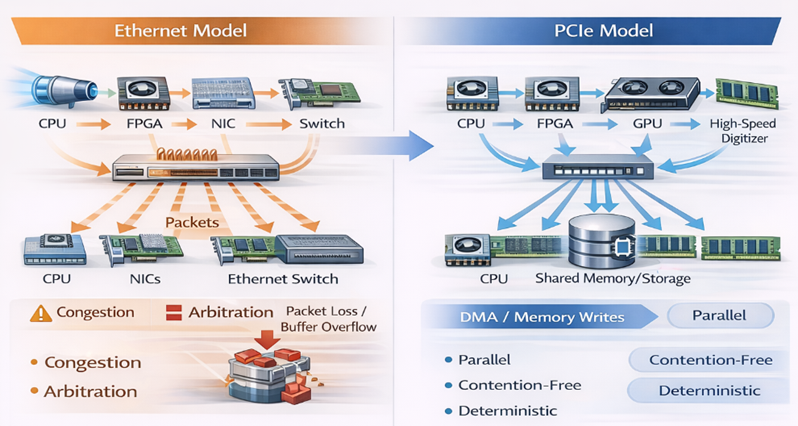
Limitations of Traditional LAN-Based Recording
In Ethernet-based architectures, writing data to centralized storage requires:
Packetization of data streams
Traversal through network switches
Processing through TCP/IP or RDMA stacks
Coordination across independent nodes
Even with technologies such as RDMA, these systems face key constraints:
Contention for shared network bandwidth
Unpredictable latency under load
Limited scalability for simultaneous writers
Complex software coordination for synchronization
As the number of data sources increases, performance degrades and data loss risk increases.
PCIe-Based Deep Memory Recording
Long-reach PCIe enables a fundamentally different approach by extending the native memory and I/O fabric across systems.
Multiple devices--including CPUs, GPUs, FPGAs, and high-speed digitizers--can:
Write directly into shared memory or storage resources
Perform simultaneous, high-bandwidth writes
Bypass network stacks entirely
Operate with deterministic timing
This model is conceptually similar to emerging memory-centric architectures such as CXL, but leverages the maturity, ecosystem, and deterministic behavior of PCIe today.
Key Advantages
True Multi-Writer Architecture
Multiple devices can write concurrently into the same memory space without packet arbitration or network contention.
Line-Rate Data Ingestion
Devices can sustain full interface bandwidth without being limited by network bottlenecks.
Deterministic Recording
Consistent latency ensures time-aligned data capture across all sources--critical for sensor fusion and post-event analysis.
Reduced Data Loss Risk
Elimination of packet drops, congestion, and retransmissions improves reliability under peak load.
Simplified Software Stack
Direct memory access reduces the need for complex buffering, queuing, and synchronization logic.
Optical Processing and PCIe: Electrifying Next Generation Sensor and Compute Architecture
The increasing importance of high-bandwidth sensing--particularly in RF, photonics, and optical domains--is driving a shift toward optical processing architectures. These systems generate and process vast amounts of data at speeds that challenge traditional electrical and network-based interconnects.
Examples include:
Photonic signal processing systems
Optical RF front ends
LIDAR and imaging pipelines
Free-space optical communications
Advanced electronic warfare platforms
Optical Processing Pipeline: LAN vs. PCIe Fabric
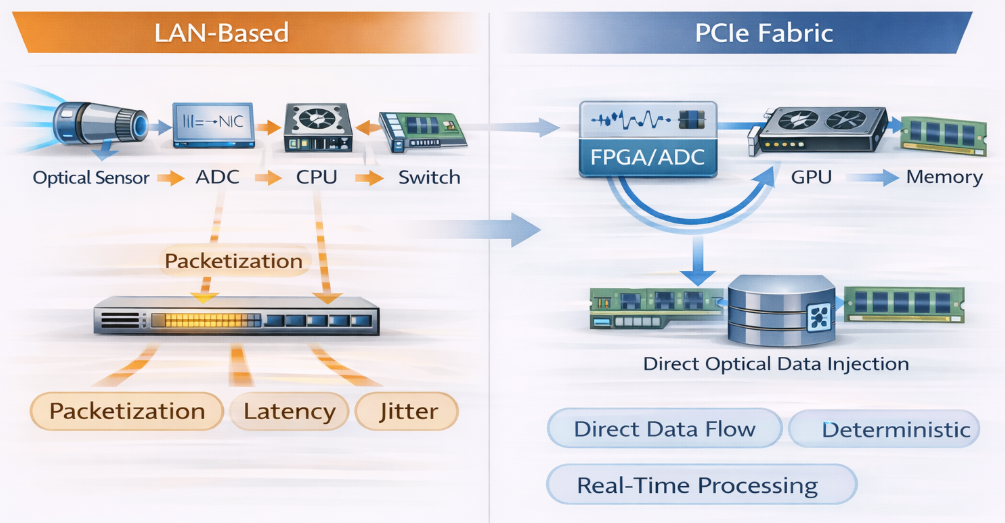
Challenges with LAN-Based Architectures
Traditional Ethernet-based systems introduce several inefficiencies when interfacing with optical processing pipelines:
Data must be converted, packetized, and transmitted through network stacks
Latency and jitter disrupt tightly coupled optical processing loops
Synchronization across devices becomes difficult
Bandwidth scaling requires increasingly complex networking infrastructure
These constraints limit the effectiveness of optical systems that depend on continuous, high-speed, and tightly synchronized data flows.
PCIe as the Electrical Backbone for Optical Systems
PCIe provides a direct, high-speed electrical interface between optical processing elements and compute resources.
With long-reach PCIe:
Optical front ends can connect directly into the PCIe fabric
Data flows as memory transactions rather than packets
Processing elements can access optical data streams in real time
Systems maintain deterministic timing across the entire pipeline
This effectively "electrifies" optical processing systems--allowing them to behave as tightly integrated extensions of the compute fabric.
Key Advantages
Elimination of Packetization Overhead
Optical data streams are ingested directly into memory without conversion into network packets.
Deterministic Processing Pipelines
Consistent latency enables precise timing alignment across optical and electronic domains.
Higher Effective Bandwidth Utilization
Bandwidth is used for payload data rather than protocol overhead.
Direct Accelerator Integration
GPUs, FPGAs, and AI accelerators can directly consume optical data streams via PCIe.
Improved System Synchronization
All components operate within a unified timing and memory model.
Reduced System Complexity
Fewer intermediate components (NICs, switches, protocol stacks) simplify system design.
As optical and photonic technologies continue to advance, PCIe-based fabrics provide a scalable and deterministic foundation for integrating these systems into next-generation compute architectures without the limitations of traditional networking.
The Emerging Compute Architecture
A hybrid architecture is increasingly common in advanced computing environments:
Inside the rack or compute cluster.
Long-reach PCIe fabrics connect compute nodes, accelerators, and memory into a unified fabric outside the rack.
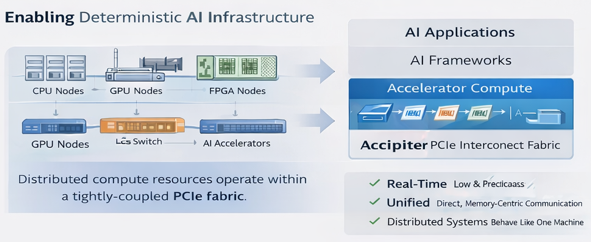
Outside the rack
Ethernet remains useful for:
Data center networking where batch processing offers acceptable performance
Remote management
External connectivity
Communication between independent clusters
This hybrid approach combines the strengths of both technologies.
Conclusion
The evolution of AI, real-time analytics, and accelerator-driven computing is exposing the limitations of traditional LAN-based architectures.
Packet-based networking introduces latency, jitter, and complexity that limit performance in tightly coupled distributed systems.
PCI Express, the native interconnect of modern compute platforms, provides a fundamentally different approach -- one based on deterministic, memory-centric communication between devices.
By extending PCIe beyond the server through long-reach fabrics, distributed computing systems can operate with the efficiency and predictability of a single coherent machine.
As AI systems continue to scale in complexity and performance requirements, long-reach PCIe architectures are emerging as a critical infrastructure technology for next-generation computing systems.
Beyond performance, long-reach PCIe significantly reduces system attack surface, offering inherent resilience against zero-day exploits that target traditional network-based infrastructures.